ACES: Abacus Cloud and Edge Systems
Project Name: Data Deduplication in Distributed Object Storage Systems Used for Cold Storage (NetApp)
This project is supported by NetApp Inc. aiming to study new technologies to enhance the storage efficiency in modern storage systems. We have been trying to achieve our goal via two methods: data deduplication and erasure coding. So far, we have got some outcomes, which have been recognized by some academic conferences.
1.SES-De-dupe: a Case for Low-Cost ECC-based SSD Deduplication
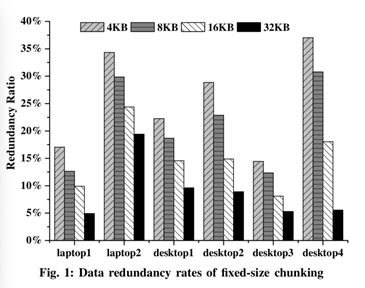
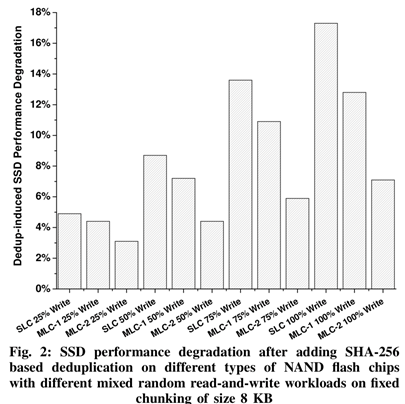
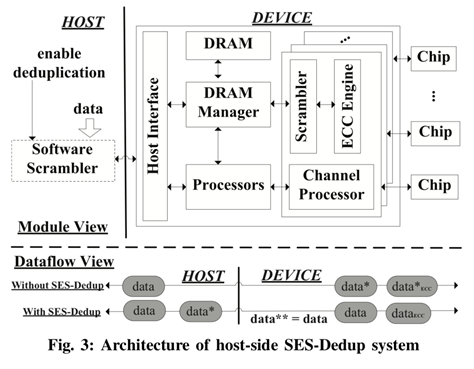
Integrating the data deduplication function into Solid State Drives (SSDs) helps avoid writing duplicate contents to NAND flash chips, which will not only effectively reduce the number of Program/Erase (P/E) operations to extend the device’s lifespan but also proportionally enlarge the logical capacity of SSD to improve the performance of its behind-the-scenes maintenance jobs such as wear-leveling (WL) and garbage- collection (GC). However, these benefits of deduplication come at a non-trivial computational cost incurred by the embedded SSD controller to compute cryptographic hashes. To address this overhead problem, some researchers have suggested replacing cryptographic hashes with error correction codes (ECCs) already embedded in the SSD chips to detect the duplicate contents. However, all existing attempts have ignored the impact of the data randomization (scrambler) module that is widely used in modern SSDs, thus making it impractical to directly integrate ECC-based deduplication into commercial SSDs. In this work, we revisit SSD’s internal structure and propose the first de-duplicatable SSD that can bypass the data scrambler module to enable the low-cost ECC-based data deduplication. Specifically, we propose two design solutions, one on the host side and the other on the device side, to enable ECC-based deduplication. Based on our approach, we can effectively exploit SSD’s built-in ECC module to calculate the hash values of stored data for data deduplication. We have evaluated our SES-De-dupe approach by feeding data traces to the SSD simulator and found that it can remove up to 30.8% redundant data with up to 17.0% write performance improvement over the baseline SSD.
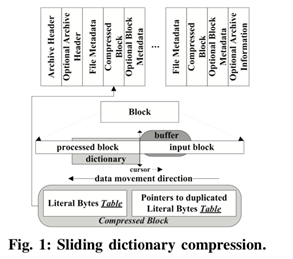
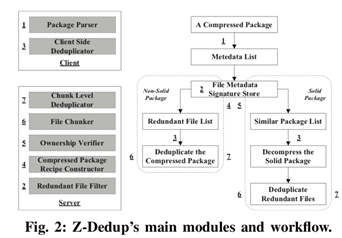
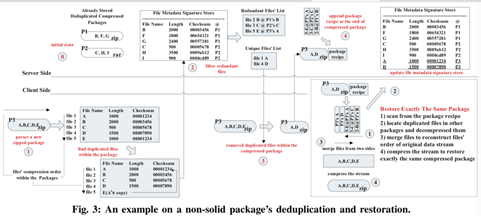
2. Z-De-dupe: A Case for Deduplicating Compressed Contents in Cloud
Lossless data reduction techniques, particularly compression and deduplication, have emerged as effective approaches to tackling the combined challenge of explosive growth in data volumes but lagging growth in network bandwidth, to improve space and bandwidth efficiency in the cloud storage environment. However, our observations reveal that traditional deduplication solutions are rendered essentially useless in detecting and removing redundant data from the compressed packages in the cloud, which are poised to greatly increase in their presence and popularity. This is because even uncompressed, compressed and differently compressed packages of the exact same contents tend to have completely different byte stream patterns, whose redundancy cannot be identified by comparing their fingerprints. This, combined with different compressed packets mixed with different data but containing significant duplicate data, will further exacerbate the problem in the cloud storage environment. To address this fundamental problem, we propose Z-De-dupe, a novel deduplication system that is able to detect and remove redundant data in compressed packages, by exploiting some key invariant information embedded in the metadata of compressed packages such as file-based checksum and original file length information. Our evaluations show that Z-De-dupe can significantly improve both space and bandwidth efficiency over traditional approaches by eliminating 1.61% to 98.75% redundant data of a compressed package based on our collected datasets, and even more storage space and bandwidth are expected to be saved after the storage servers have accumulated more compressed contents.
3.Efficient Lowest Density MDS Array Codes of Column Distance 4
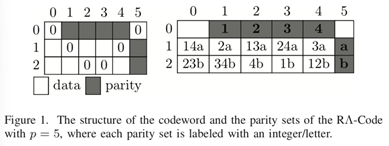
The extremely strict code length constraint is the main drawback of lowest density, maximum-distance separable (MDS) array codes of distance greater than 3. To break away from the status quo, we proposed in [5] a family of lowest density MDS array codes of (column) distance 4, called XI- Code. Compared with the previous alternatives, XI-Code has lower encoding and decoding complexities, and much looser constraint on the code length, thus is much more practical. In this paper, we present a new family of lowest density MDS array codes of (column) distance 4, called RΛ-Code, which is derived from XI-Code, and outperforms the latter substantially in terms of encoding complexity, decoding complexity, and memory consumption during encoding/decoding. The inherent connection between RΛ-Code and XI-Code and how the former is derived from the latter may provide inspiration for the readers to derive new codes from other existing codes in a similar way.
4. Efficient MDS Array Codes for Correcting Multiple Column Erasures
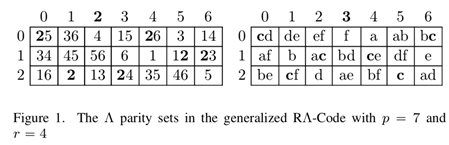
The RΛ-Code is an efficient family of maximum distance separable (MDS) array codes of column distance 4, which involves two types of parity constraints: the row parity and the Λ parity formed by diagonal lines of slopes 1 and ́1. Benefitting from the common expressions between the two parity constraints, the encoding and decoding complexities are distinctly lower than most (if not all) of other triple-erasure-correcting codes. It was left as an open problem generalizing the RΛ- Code to arbitrary column distances. In this paper, we present such a generalization, namely, we construct a family of MDS array codes being capable of correcting any prescribed number of erasures/errors by introducing multiple Λ parity constraints. Essentially, the generalized RΛ-Code is derived from a certain variant of the Blaum-Roth codes, and hence retains the er- ror/erasure correcting capability of the latter. Compared with the Blaum-Roth codes, the generalized RΛ-Code has two advantages: a) by exploiting common expressions between row parity and different Λ parity constraints, and reusing the intermediate results during the syndrome calculations, it can encode and decode faster; and b) the memory footprint during encoding/decoding, and the I/O cost caused by degraded reads, are both reduced by 50%.