ACES: Abacus Cloud and Edge Systems
MSLO-JS: Towards Multi-SLO-Guaranteed per-Job Scheduling in Datacenters
MSLO-JS is cross layer by design, involving a two-layer design. At the upper, application layer, a mathematical foundation is developed to allow any Service Level Objectives (SLOs) for a Directed Acyclic Graph (DAG) sturctured job work flow to be translated into task latency-related budgets at the individual nodes in the DAG. The design at this layer is independent of the underlying systems to be used. At the lower, runtime system layer, the subsystems corresponding to the task nodes in the DAG are selected and the resources are allocated. The objective is to ensure that all the subsystems meet their respective task and compenent budgets, which will then guarantee that all the SLOs for that job are satisfied. The two layers are decoupled purposely to allow SLO-to-budget translation to be developed, independent of the underlying subsystems to be used.
DAG structured query work flow
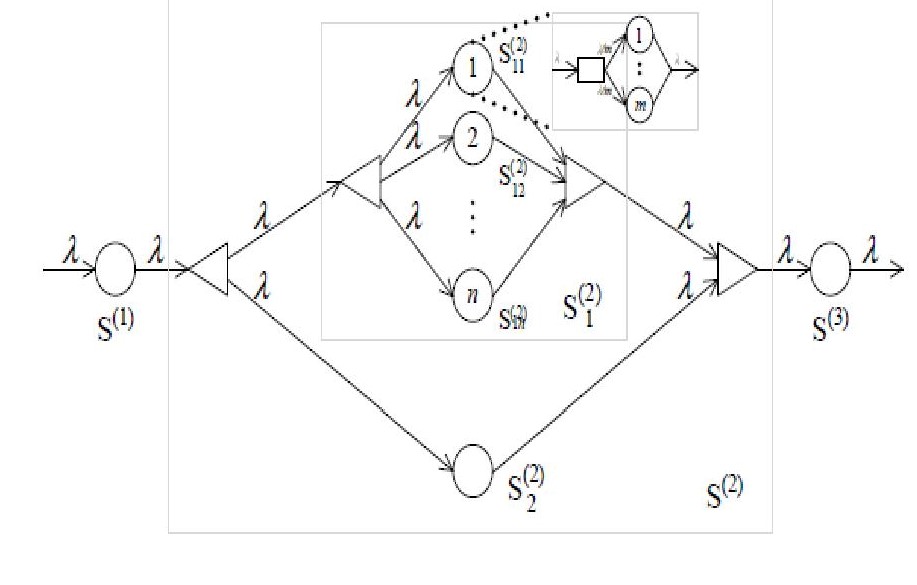
Above figure shows a typical query DAG including multiple stage Fork-join processes. A key challenge is how to allocate computing resources to different tasks to meet the query SLO requirement while maintaining high resource utilization.
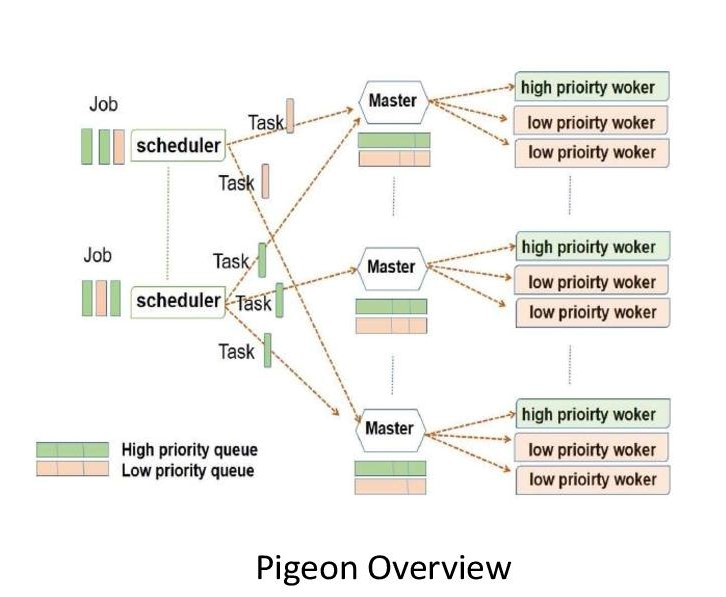
Pigeon: a distributed hierachical datacenter job scheduler
We first develop a distributed, hierarchical job scheduler, Pigeon, to effectively handle heterogeneous jobs in datacenters. Pigeon divides workers into groups,
each managed by a separate master. In Pigeon, upon a job arrival, a distributed scheduler directly distribute tasks evenly among masters with minimum job processing overhead, hence,
preserving highest possible scalability. Meanwhile, each master manages and distributes all the received tasks centrally, oblivious of the job context,
allowing for full sharing of the worker pool at the group level to maximize multiplexing gain. To minimize the chance of head-of-line blocking for short
jobs and avoid starvation for long jobs, two weighted fair queues are employed in in each master to accommodate tasks from short and long jobs, separately,
and a small portion of the workers are reserved for short jobs. Pigeon can effectively handle short jobs while maintaing high effiency for long jobs.
SLO guaranteed single stage job scheduling
For a Fork-join job with multiple tasks, the p-th percentile tail latency requirement Tp for the job can be translated to
the task budget (the mean of all the task completion time Ep and its variance Vp).
If the mean task completion E < Ep and its variance V < Vp, then the p-th percentile tail latency is satisfied.
Denote rj,k as the computing rate for k-th task ( k=1, …, kj ) belonging to the j-th job ( j=1, …,NJ )
and NJ is the number of active jobs. For job j with a tail latency demand, a task completion budget (Ej,k) is obtained.
A SLO-guaranteed job scheduling is to allocate at least ( rj,k = Wj,k / Ej,k is the task computing size ) computing resource to task k in job j,
and then the SLO tail latency is met. The job tail latency requirement is integrated into Pigeon job scheduler to provide SLO guarantee.
Applying the task budget estimation in Pigeon, a task preempty job scheduling is developed to guarantee the job tail latency requirement.
SLO guaranteed DAG query scheduling
For a query with multiple stage Fork-join processes in a DAG, the query completion time budget is first decomposed into job completion time budget for each stage job along each path in the DAG.
Then the job completion time budget in each stage is further translated into task completion budget as a single stage job.
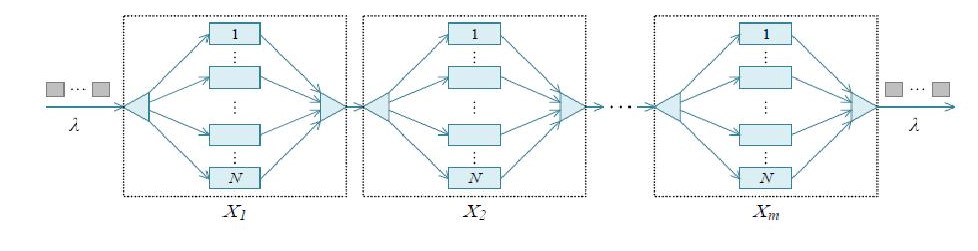
The above figure show a path in a query with m Fork-join processes. The overall time budget for a query (E,V) is decomposed into
time budgets for each job ( E1, V1 ), …, ( Em, Vm ) in the DAG.
Then the time budget for job j is further translated into task budget as a single stage job. The tail latency guaranteed job schedluer integrated
with Pigeon framework can be applied for multi-stage job scheduling to provide tail latency guarantee.