-
Is the following function P a valid probability function? If you answer
"no", explain why not.
P(day == Monday) = 0.4
Answer:
P(day == Tuesday) = 0.4
P(day == Wednesday) = 0.2Yes.
- Is the following function P a valid probability
function? If you answer "no", explain why not.
P(day == Monday) = 0.4
Answer:
P(day == Tuesday) = 0.4
P(day == Wednesday) = 0.2
P(day == Thursday) = 0.1No, because the sum of probabilities is 1.1, it should be 1.
- Is the following function P a valid probability density
function? If you answer "no", explain why not.
P(x) = 0.1, if 10 <= x <= 20.
Answer:
P(x) = 0 otherwise.Yes.
- Is the following function P a valid probability density
function? If you answer "no", explain why not.
P(x) = 0.01, if 10 <= x <= 20.
Answer:
P(x) = 0 otherwise.No, because the integral of P from -infinity to + infinity is 0.1, it should be 1.
P(alarm | fire) = AAnswer:
P(alarm | not fire) = B
P(fire) = C
P(fire | alarm) = P(alarm | fire) * P(fire) / P(alarm) = A * C / P(alarm).So, if we set D = P(alarm) = A * C + B * (1 - C), our final answer is:
P(alarm) = P(alarm, fire) + P(alarm, not fire)
= P(alarm | fire) * P(fire) + P(alarm | not fire) * P(not fire) =
= A * C + B * (1 - C)
P(fire | alarm) = A * C / D
P(fire) = 0.1
P(earthquake) = 0.2
P(flood) = 0.4
- Suppose that we do not know whether fire, earthquake,
and flood, are independent events. Can we compute the probability
P(fire and earthquake and flood)? If yes, what is P(fire and earthquake
and flood)?
Answer:
No, if we do not know whether fire, earthquake, and flood, are independent events, then we would need some additional information (such as a joint distribution table) to compute P(fire and earthquake and flood).
- Suppose that we know that fire, earthquake, and flood,
are independent events. Can we compute the probability P(fire and
earthquake and flood)? If yes, what is P(fire and earthquake and
flood)?
Answer:
Yes.
P(fire and earthquake and flood) = P(fire) * P(earthquake) * P(flood) = 0.1 * 0.2 * 0.4 = 0.008.
- Suppose that we know that fire, earthquake, and flood,
are not independent events. Can we compute the probability P(fire and
earthquake and flood)? If yes, what is P(fire and earthquake and
flood)?
Answer:
No, if we know that fire, earthquake, and flood are not independent events, then we would need some additional information (such as a joint distribution table) to compute P(fire and earthquake and flood).
Commute time 40-60 Fahrenheit 60-80 Fahrenheit above 80 Fahrenheit
< 20 min 0.1 0.05 0.1
20-40 min 0.2 0.1 0.1
> 40 min 0.05 0.1 0.2
Answer:
P(commute time < 20 min | temperature > 80) = P(commute time < 20 min AND temperature > 80) / P(temperature > 80)
P(commute time < 20 min AND temperature > 80) = 0.1
P(temperature > 80) = 0.1 + 0.1 + 0.2 = 0.4
P(commute time < 20 min | temperature > 80) = 0.1 / 0.4 = 0.25
Answer:
We expect that P(Earthquake | Alarm) is larger than P(Earthquake | Alarm and Burglary). Burglary and Earthquake are competing causes for the Alarm event. Given that Alarm is true, if we know that one possible cause (Burglary) is true, the other competing cause (Earthquake) becomes less likely.
Answer:
P(Earthquake | Alarm) is equal to P(Earthquake | Alarm and MaryCalls). Earthquake and MaryCalls are conditionally independent given the value for the Alarm event.
- 40 people bought minivans. Out of those 40 people, 30 people were over 35 years of age, and 10 people were under 35 years of age.
- 60 people bought regular cars. Out of those 60 people, 12 people were over 35 years of age, and 48 people were under 35 years of age.
Answer:
We call "parent" the node with the 100 training examples, "child1" the child node that receives the examples where the age is over 35 years, and child2 the child node that receives the examples where the age is under 35. Node child1 receives 42 examples, and node child2 receives 58 examples. We denote by log2(x) the logarithm base 2 of x. Then:
Entropy gain = Entropy(parent) - 42/100 * Entropy(child1) - 58/100 * Entropy(child2).
Entropy(parent) = -0.4 * log2(0.4) - 0.6 * log2(0.6) = 0.971
Entropy(child1) = -(30/42) * log2(30/42) - (12/42) * log2(12/42) = 0.8631
Entropy(child2) = -(10/58) * log2(10/58) - (48/58) * log2(48/58) = 0.6632
Entropy gain = Entropy(parent) - 42/100 * Entropy(child1) - 58/100 * Entropy(child2)
= 0.971 - 0.42 * .8631 - 0.58 * 0.6632
=> Entropy gain = 0.2238
Answer:
If there are no duplicate training examples (i.e., if no two training examples have exactly the same values for all attributes), then the answer is yes. If there are two training examples with exactly the same values for all attributes but different class labels, then the answer is no.
Answer:
P(A | vanilla) = P(vanilla | A) * P(A) / P(vanilla) = 0.2 * 0.99 / P(vanilla)Consequently:
P(vanilla) = P(vanilla AND A) + P(vanilla AND B)
= P(vanilla | A) * P(A) + P(vanilla | B) * P(B)
= 0.2 * 0.99 + 0.6 * 0.01
= 0.2040
P(A | vanilla) = P(vanilla | A) * P(A) / P(vanilla) = 0.2 * 0.99 / 0.204 = 0.9706
Answer:
X1 >= X2 + 5 => X1 - X2 - 5 >= 0Therefore our neuron will have the following weights:
- Weight 5 for the bias input (as a reminder, the bias input is always -1).
- Weight 1 for X1.
- Weight -1 for X2.
Answer:
No, we cannot. Consider these two cases:
- Case 1: X1 = 1, X2 = 1. In this case, increasing X3 from 0 to 1 decreases the output from 1 to 0.
- Case 1: X1 = 1, X2 = 0. In this case, increasing X3 from 0 to 1 increases the output from 0 to 1.
When the exact same change to an input leads (given appropriate values to the other inputs) to opposite changes in the output, then the function cannot be modeled by a neuron.
Answer:
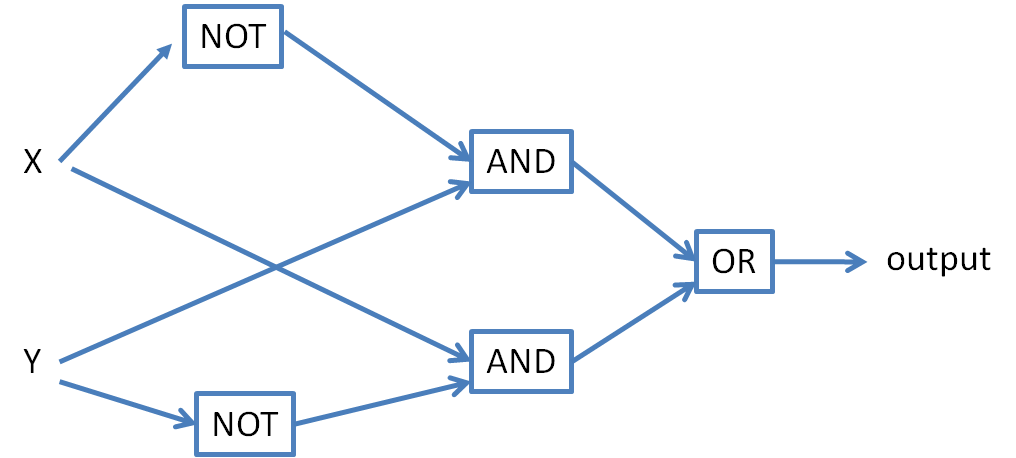
(X XOR Y) = ((X AND (NOT Y)) OR ((NOT X) AND Y)).Consequently, using the AND, NOT, and OR neurons as defined in the textbook, the neural network for XOR looks like this: