Hello,
My name is Deokgun Park and I lead Human Data Interaction Lab (HDILab) in the Department of Computer Science & Engineering at the University of Texas at Arlington. In this article, I will explain the problems we are solving at HDILab. In Human Data Interaction Lab, we are studying artificial general intelligence (AGI).
Many students already have an idea about artificial intelligence (AI). But artificial general intelligence or AGI might be a new term. So let’s start with what AGI is.
Clarifying AI and AGI
Since Marvin Minsky and other researchers gathered at Dartmouth College in Hanover in 1956, the goal of AI was to build a machine that can do many tasks like humans. But after experiencing a few AI winters, the academic focus shifted to building models to perform a single application because it was more tractable. This approach has been frequently called machine learning (ML). It is said that one of the reason ML has been coined was to avoid mentioning AI in the proposal during the AI winters. It was successful, and we achieved many advances in specific applications such as image classification, machine translation, self-driving car, or playing Go game. And the term AI became hot again.
But we still lack an idea about how we can build a general-purpose AI which appears in Hollywood movies or general public associates with. Because most of the current AI research is application-specific, we need another term for the original general purpose agent. It has been rephrased many times, including
- strong AI
- true AI
- human-like AI
- movie-like AI
- lifelong learning
- continual learning
- meta learning or learning to learn
- artificial general intelligence (AGI)
We will use AGI to refer this original AI because it tells the fundamental difference between the current mainstream AI research, which is application-specific.

AI vs AGI. AI started as a general purpose model, but later changed its meaning to mostly application specific models. We will use artificial general intelligence (AGI) to mean the original general purpose model.
How to test AGI
Before we discuss how we can build AGI, let’s start with how we can test if we built AGI. Because according to Peter Drucker or Lord Kelvin,
If you can’t measure it, you can’t improve it.
Alan Turing suggested a test to verify AGI. According to the Turing test, also known as Imitation Game, a human participant asks an agent hidden behind the wall to perform many tasks. If the human cannot discern whether the agent is truly a human or an artificial agent, then the artificial agent is assumed to achieve a human-level intelligence.

In the movie Ex Machina, you can see how Turing test is conducted.
While theoretically valid, it poses several problems in its practical application. First, it is too difficult for the current status of research. The human tester can use all the knowledge about the world to test the agent, yet it would be very costly and impossible to teach all the knowledge about the world to the artificial agent, while researchers struggle to discover how we can mimic human-like learning. It is like asking a 1st grader to take SAT test.
Second, the test does not provide any idea about where the model can learn those knowledges required to take test. It is like testing students without giving them any textbooks or lectures.
Third, even for the same model and the same evaluator, the feedback will be different from today to tomorrow. The test is subjective and not reproducible.
Finally, it is prohibitively expensive to hire people to conduct a test. Humans may participate in annual Turing test competition, but during the hyperparameter tuning or iterative model refinement, it is difficult to get access to human testers. For these reasons, it is not practically applicable in the current renaissance of the AI.
We propose an alternative test method for AGI. This method is based on the observation that even if we raise cats and dogs, treating them like human babies, they cannot learn to speak. The animals are capability-limited, and the human baby cannot learn to speak if it is separated from people speaking to it. It is environment-limited. Therefore we can think that the language acquisition is the function of the environment and the capability of the learning agent. In other words, if an agent can learn how to speak in a proper environment, we can say that it has the capability to do artificial general intelligence. We call it the Language Acquisition Test for AGI or Park’s test.
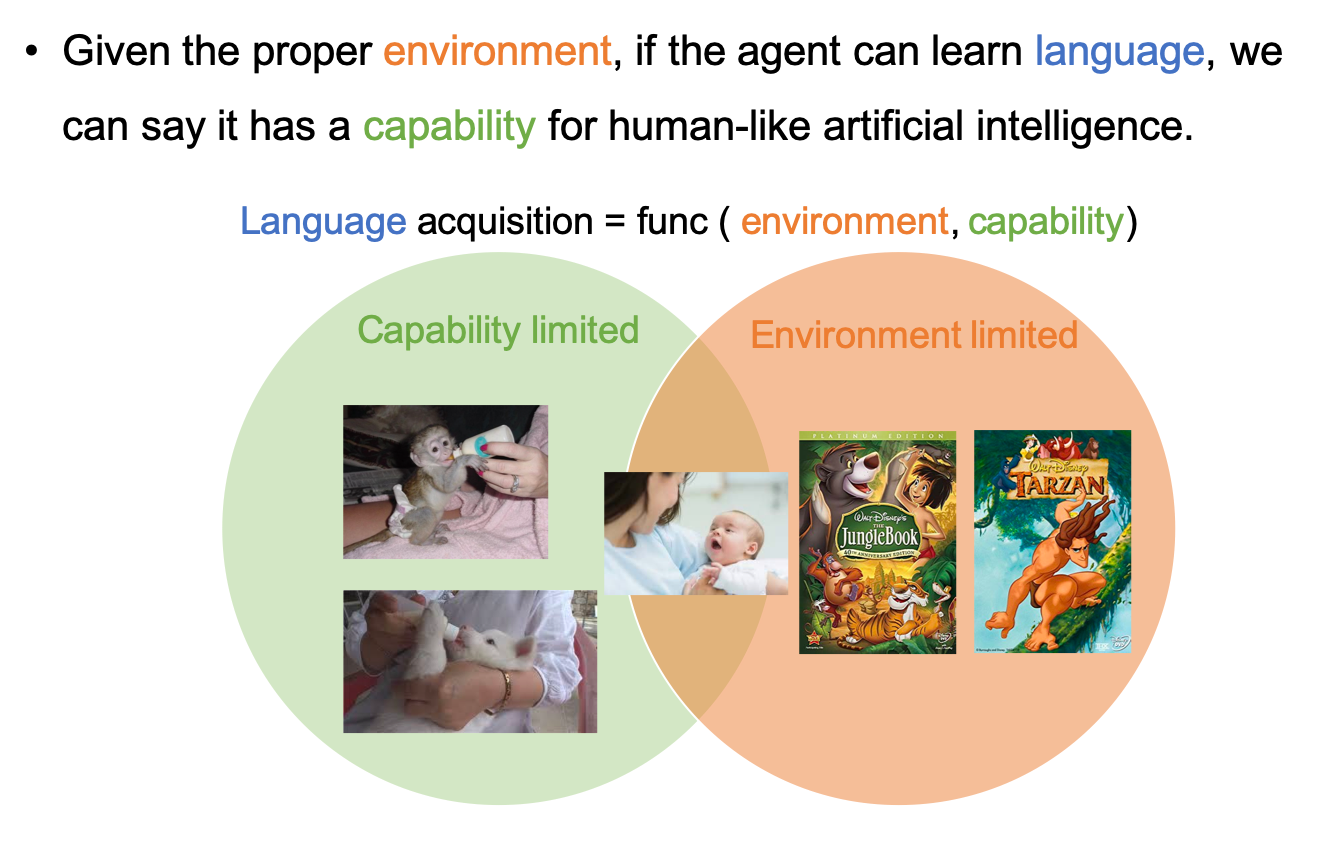
In Park’s test, the agent is said to have a human-level intelligence if it can learn language given the proper environment
To pass a Park’s test, we needs a capable model and a proper environment. Let’s look at environment first.
The Environment for the Language Acquisition
To conduct the Park’s AGI Test, an agent requires an interaction with the world to learn how to speak. One factor that enabled the recent advances in reinforcement learning was the use of the simulated environments such as Atari games or 3D first person shooting games such as VizDoom. Those environments can be used to build and test an agent that can optimize its behavior with little instructions while maximizing the reward signal as a goal to train an agent. However, environments and reward signals adopted in those studies are primitive and more suitable for the development of low-level intelligence which can be found in fish or bugs.
| Atari Environment | Car Racing Environment | RoboSchool Environment |
If we want to build an agent with human-level of intelligence, we need to use an environment that can provide a reasonable sensory input and feedback that can teach an agent how to speak. One naive way to provide such an environment is using real people to provide the required responses or trainings. However, using real people has similar limitations with the Turing test. We will have to explore many models in a trial and error before we can finally build an AGI. In addition to the prohibitive cost of using human participants, human experimenters will become quickly tired of providing the same feedback again and again or providing different feedback to the same situation which does not lead to reproducible research.
| Advanced Discussion: What is language? |
|---|
| Some would claim that the poor baby abandoned in jungle will still develop a language to communicate with other animal. Similarly there is an emergent communication pattern among collaborative robots. While true, we are interested in human language in this project especially for human robot interaction. The rationale is that we want the robot to learn human language not vice versa. |
There are a few prior researches in language acquisition. Devendra Singh Chaplot and other researchers in the Carnegie Melon University used VizDoom environment to demonstrate how agent can learn semantic concepts using reinforcement learning. In their experiments, agents get rewards when they go to objects according to the verbal direction such as “Go to short blue torch”. What is interesting is that during the training the agents experience verbal direction such as “Go to blue torch”, “Go to torch”, “Got to short red torch” and so on but never experience “short blue torch”. Even then during the test time, they can follow the direction to go to “short blue torch”. This implies that the agent can map the words such as “short”, “blue”, “torch” with the visual features in the objects. This is a step forward to solve the symbol grounding problem.
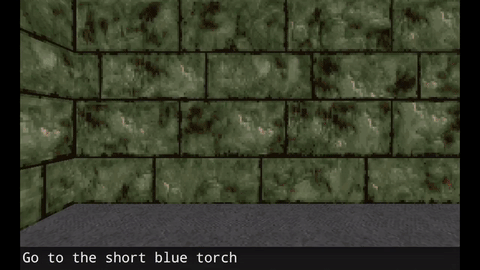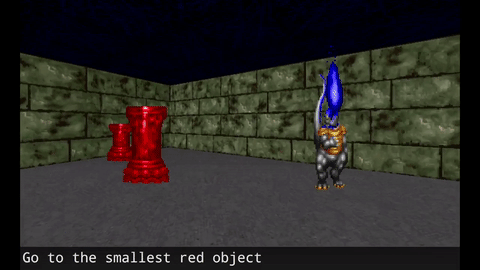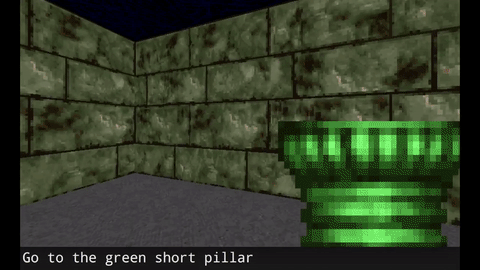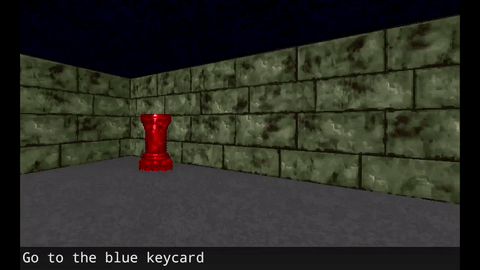
Agents learns language using reinforcement learning. Image by Devendra Singh Chaplot et al
But the concepts that can be learned in this way is limited. There are limitations due to the environments. We don’t learn by fetching objects according to the parent directions. It will take too long to learn all concepts this way. We need a better environments that can teach the language
When the transistor was first invented, people were excited to use it as an amplifier to build radio and radars. But the true power of the transistor was when it was arranged in a specific structure, it could build a logic gate. By arranging logic gates in a specific way, we could build a CPU, the true ultimate power of transistor.
The same goes with the connectionism. We know how one or two neural cell behaves exactly and we can simulate them. But most advancement came with the arrangement of this device in a specific ways, such as multi-layer perceptron (MLP), convolutional neural net (CNN), recurrent neural net (RNN), and generative adversarial network (GAN). In this sense, we are experimental computer scientist who seek the right structure mostly by trial and errors. Because of this nature, it is helpful to have an environment that can provide an easy, low-cost, and reproducible way to experiment.
In our lab, we would like to develop an environment for Park’s test. The key idea is that we will focus on the critical stage of the human development when humans learn how to speak as infants. This environment will contain a 3D replication of a room in the home with a few toys. There will be a mother character and a baby character. The mother character will be programmed manually using traditional game AI technology to take care of the baby and lead a conversation with the baby character which is often called a baby talk, child-directed speech (CDS), motherese or infant directed speech (IDS). IDS is a communication pattern, when a mother tries to teach language to an infant. The baby character will be the learning agent. The success of the test will be decided by whether the learning agents can acquire language and develop reasonable behavior comparable to the human developmental progress.

Previous environments have led the advancements of the reinforcement learning. We propose a novel environment for the language learning.
Hierarchical Prediction Memory (HPM)
HDILab also studies the model that can learn the language in the environment described above. Let’s start our discussion from the function and the mechanism.
Function and Mechanism
The most difficult way to fly is to imitate the biological mechanism of flying such as in birds or flies. The biological mechanism is highly evolved due to the long history of adaptation. And many of the complex mechanism is due to the biological limitation which does not apply to us. What we need to figure out is what those mechanism are actually doing or function. The way human or horses run is pushing the ground backward. The way birds fly is pushing the air downward. This applies to the intelligence. The biological mechanism is very complex. It has been very optimized. It has to use biological lossy devices. So the mechanism is very complex. But we need to learn what is the function of the mechanism. It is in my opinion prediction of vector sequence. Hierarchy helps to overcome the temporal limit by chunking. The essence of intelligence is hierarchical prediction of vector sequence.
We conjecture that the essence of the intelligence is a hierarchical prediction.
Where the original connectivist has missed? The original connectivist thought the decision or pattern recognition as the core activity. However, this lead to the wrong formalization of the problem? In my opinion, prediction should be the core activity. Prediction includes the decision or pattern recognition, but the main difference is that it has the streaming input and streaming output.