This is the paper review of the following paper.
Rinkus, Gerard J. “A cortical sparse distributed coding model linking mini-and macrocolumn-scale functionality.” Frontiers in neuroanatomy 4 (2010): 17.
I found this paper while searching for the sparse coding implementation. His work claimed 91% performance on MNIST and 67% on Weizmann event dataset. While this result is weaker than the state of the art result (around 99%), the following aspects were interesting.
First, Sparsey model uses sparse distributed representation (SDR) rather than dense representation. Second, Sparsey model does not use any of optimization including gradient back propagation. It can do one-shot learning meaning that only one example is required for learning. Actually, the weights between neurons are binary and they are set by single occurence in Hebbian manner. These two attributes are what I were considering required for my model. Only comparable model is HTM by Numenta. However, HTM does not have any performance evaluation result with popular dataset except a few synthetic toy dataset.
The main algorithm transforms binary inputs into sparse distributed representation.
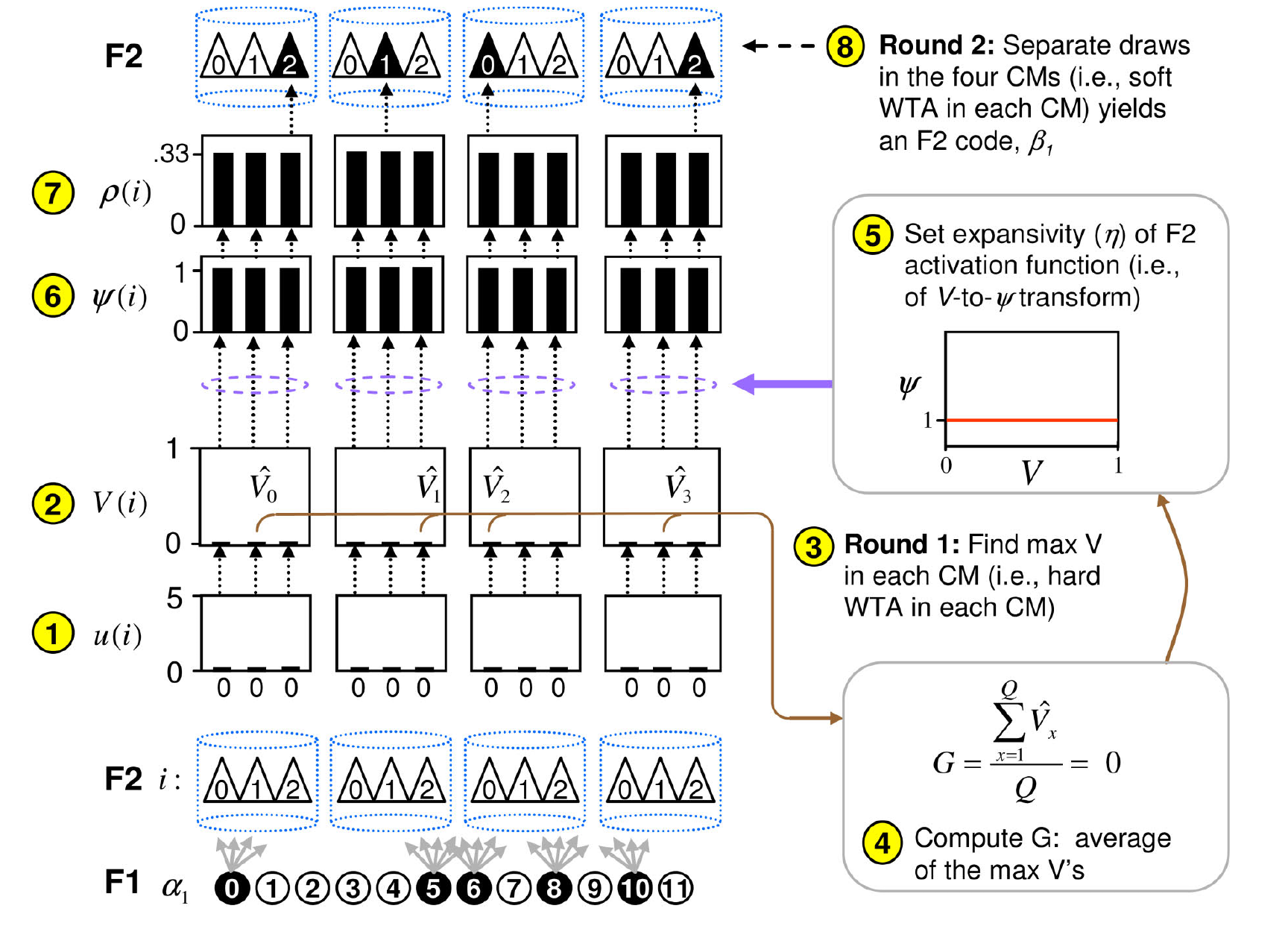
The sparsey algorithm produces sparse distributed representation (SDR) from the binary inputs. If the input patterns are very similar to previous patterns, the resulting SDR code will be almost same to previous codes while novel patterns will result in novel code.
The key insight is that the algorithm uses the familarity or novelty measure to control randomness of the resulting code. As a result, a well-known code or familar codes result in same representation as the previous case while the novel code results in the different code. The author calls it similar inputs map to similar codes (SISC).
There were many neuroscience references which will be useful for my future research. For example, cells in the minicolumn possesses simiar receptive field characteristic or tuning. This fact is also utilized in the HTM and cloned HMM. The cells in the column shares the same inputs.
Also SDR is used in the cells as can be shown in below figure.

The Calcium images of L2/3 of rat visual cortex reveals sparse distributed representation (SDR). Images from Ohki et al (2005).
One big question for me is that if we define SISC as the binary bit overlap, the incoming input already possess the SISC property. While the algorithm creates more sparse version of the binary input, how the sparse representation can be utilized is a big question.
Is the simplication the core process the cortical columns are doing? In my opinion, the prediction is the main task. After several hierarchy, the mnist digits might be separated to constant representation, but it does not tells about how the motion should be generated.
As a conclusion, this paper provides a good rationale behind the use of SDR verus dense or local code. But the model is not good for my purpose. I will look at the logistic regression with Lasso regularization as the next candidate.
Below is my mindmap for the related papers to artificial general intelligence.