This is the paper review of the following paper.
Legg, Shane, and Marcus Hutter. “Universal intelligence: A definition of machine intelligence.” Minds and machines 17.4 (2007): 391-444.
While I was working on new paper on the language acquisition test, I needed a definition of intelligence. I had my own simple informal definition as an ability to behave in a beneficial way according to the sensory input. Though I am happy with my definition, academia is all about not reinventing the wheel and giving a proper credit to original authors.
At first I was worried because intelligence is an abstract concept and there have been a lot of ideas in the history of AI and psychology. R. J. Sternberg said that
Viewed narrowly, there seems to be almost as many definitions of intelligence as there were experts asked to define it.
Some pose practical stance that the definition is not important as long as we can recognize it when we see. Chris Eliasmith suggested that cognition is to researchers what pornography was to justice Potter Stewart in his book1.
Potter Stewart said
I shall not today attempt further to define pornography and perhaps I could never succeed in intelligibly doing so. But I know it when I see it.
We could replace cognition with intelligence without loss of generality.
Therefore when I found the paper by Shane Legg and Marcus Hutter, it was quite pleasant relief. Authors surveyed many definitions from the literature. Actually there is a companion paper2 which shows the collection of the definitions of intelligence. In that paper, they collected 71 definitions from the dictionary, psychologist, and AI researchers.
Based on this survey, they propose an informal definition of intelligence as following.
Intelligence measures an agent’s ability to achieve goals in a wide range of environments.
What is nice about this definition is that this definition is universal meaning that it can be applied to humans, animals, and computer systems. Historically, intelligence is the term to describe human intelligence especially in the context of human intelligence test. Therefore many definitions and tests are anthropocentric. Many definitions also try to list the specific elements of the intelligence. It is like for definition of speed, listing the elements of vehicle such as engine, tire, and suspension and so on. One such example is following:
“Intelligence is a very general mental capability that, among other things, involves the ability to reason, plan, solve problems, think abstractly, comprehend complex ideas, learn quickly and learn from experience. “ 3
Here the ability to reason, plan, solve problems, think abstracly, etc. are all examples of the components for intelligence. Especially learning is a major component, where many people think essential for intelligence. But authors insist that learning is just one possible strategy to achieve goals in a wide range of environments even though it is an important and widely adopted in human and animals. And I agree with this view. For example, a worm can respond to various sensory input to achieve goals. But the individual agent does not learn but the species as a whole optimizes the neural circuitry with genetic evolution.
Another common pattern is shifting the problem to other abstract terms such as thinkging, creativity, consiousness or imagination. The follwoing examples shows this pattern:
The ability to carry on abstract thinking. (L. M. Terman)
The capacity for knowledge, and knowledge possessed. (V.A.C. Henmon)
The authors also try to derive a formal mathematical definition from the informal definition. Authors builds on the reinforcement learning (RL) framework of environment, agent, reward, observation, and action. The following figure shows a typical setup in the RL.

Environment provides the observation and reward and the agents processes it to select appropriate actions
Given an environment $\mu$ and agent $\pi$, the expected future value is the sum of discounted rewards into the infinite future where $r_i$ is the reward in cycle i of a given hstory, $\gamma$ is the discount rate, and $\Gamma$ is the normalizing constant $\Gamma := \sum_{i=1}^{\infty}\gamma^i$.
$$V^{\pi}_{\mu}(\gamma):=\frac{1}{\Gamma}\mathbf E\left(\sum_{i=1}^{\infty}\gamma^ir_i\right) $$
This is the expected total reward for one environment. How we can represent diverse environment? More challenging question is how we can quantify an easy environment and a complex environment. Also how should we assign an weight to the performance (expected reward) for easy and difficult environment?
The main idea authors suggest is that the complexity of environments can be expressed with Kolmogorov complexity of the binary string that describes the environment.
$$ K(x) := {min}_p \{ l(p): U(p) = x \} $$
You can think of the binary string p as the program to simulate the environment for the reference universal Turing machine U. Kolmogorov complexity is then the minimum length of the program that runs in Turing machine U. Generally if the length of program is short, the program is simple. And in this case, the fact that we have to find the minimum length makes the computation intractable for non-trivial case. You can think Kolomgorov complexity is similar with minimum description length (MDL) for program.
When there are many environments, what is the probability distribution for the environment? One idea is that the probability of the existence of environment $p_{\mu}$ might be inversely proportional to the exponential of the length or $p_{\mu} \propto 2^{-K(\mu)}$. You might imagine randomly appending 0 or 1 to binary string to build a program. Therefore we can express intelligence as the expected performance of agent $\pi$ with respect to the probability of environment $ 2^{-K(\mu)}$ over the space of all environments E.
$$ \Gamma(\pi) := \sum_{\mu \in E}2^{-K(\mu)}V^{\pi}_{\mu}$$
Authors define this as the universal intelligence of the agent $\pi$. Authors then compare the intelligence of following agents.
- A random agent
- A very specialized agent
- A general but simple agent
- A simple agent with more history
- A simple forward looking agent
- A very intelligent agent
- A super intelligent agent
- A Human
It is quite nice to see that a very specialized agent gets lower intelligence score than a general but simple agent. Later the authors surveys the tests for the intelligence because the definition and the test are closely related in many cases. The list of tests are also useful for my research.
- Turing test and derivatives: Common criticism is that Turing test is not necessary to establish intelligence. Because the required knowledge level is too high, it cannot offer much guidance to the AI research. Also it depends on the human judges who are not reliable and reproducible for repeated tests.
- Compression tests: Compression can also represent the intelligence. An example would be summarizing papers, describing movies and so on.
- Linguistic Complexity: HAL project propose to “measure a system’s level of conversational ability by using techniques developed to measure the linguistic ability of children such as vocabulary size, length of utterances, response types, syntactic complexity and so on.
- Multiple Cognitive Abilities: Toddler turing test tries to build a young child in a similar set up to Turing test. A2I2 project tries to test performance of a small mammal. I would need to check this tests.
- Competitive Games: The goal is to build an AI that can do well on multiple games. This approach is popular nowadays.
- Collection of Psychometric Tests: This aims to pass the intelligence test for human such as Wechsler adult intelligence scale.
- C-Test: It is similar concept to universal intelligence. But the test environment is limited to sequence prediction and sequence abduction tasks. Using Levin complexity, we can measure the complexity of the each problems.
- Smith’s Test: An algorithm generates a series of problems for an agent. When the answer is wrong, the agent might try another answer to the same problem.
And authors suggest useful properties for tests of machine intelligence and score each tests according to the properties. Below is the summary.

Comparison of various tests for machine intelligence.
Please note that Kolomogorov complexity is intractable for non-trivial case, therefore universal intelligence is a definition not test.
If we apply this metric to the Language acquisition test, I think the following can be claimed.
- Valid: debatable because it only measures language acquisition but we claim it is the core of human-level intelligence
- Informative: debatable for we provide many scores written as vectors.
- Wide Range: No
- General: No. because we target for human-level intelligence.
- Dynamic: Yes because the agent learn and adapt over time
- Unbiased: No because SEDRo is biased to human in western culture.
- Fundamental: Yes
- Formal: No because it is difficult to judge whether an agent has acquired language or not.
- Objective: No because we have to rely on the human judges.
- Fully Defined: No. The environment and the objective is not fully defined.
- Universal: No. It is anthropocentric.
- Practical: Yes because we are using simulator.
- Test vs Def: Test.
Finally in the paper, the authors response to common criticisms. Among those, I liked how they respond to “Blockhead” argument and “Chinese room” argument. To introduce those arguments to the readers, “Blockhead” argument is that a machine seems to be intelligent to pass the Turing test, but it it is in fact no more than just a big look-up table of questions and answers. This machine with simple look-up table does not seems to be intelligent, isn’t it? The “Chinese room” argument is similar. The agent in the room responds to the questions in chinese. But the agent cannot understand chinese character. But it has a big book of Chinese phrasebooks with questions and matching answers. Therefore when the agent is given the question in the chinese letter, the agent will simply search the book for the same phrase and write answer and send it back. Even though the agent pass the Turing test, does the agent understand chinese?
The authors claim that as long as the agent shows high $\Gamma$ value, the internal working does not matter.
… it is not even clear to us how to define understandings if its presence has no measurable effects. … if understanding does have a measurable impact on an agent’s performance in some well defined situations, then it is of interest to us. In which case, because $\Gamma$ measures performance in all well defined situations, it follows that $\Gamma$ is in part a measure of how much understanding an agent has.
Personally I think these arguments are harmful influence of philosophers to engineering discipline. I agree with authors. So far, I have talked about the contents of the paper and what I liked in the paper. Now let’s talk about my criticism.
My criticism
While I agree with their informal definition, my main criticism lies in their formal definition. I think it has a faulty assumption that rewards are equivalent to the goals. Reward system is just one of a trick to achieve goals.
Intelligence is the concept that originated from biological agent. Therefore goals are natural to explain in perspective of biological agent. Generally we can say that the goal is to spread gene. Intelligence is one of strategy to achieve this goal. What are other strategies? Virus or bacteria have the strategy for lowering the cost of replication by hijacking to other system. Plant or phytoplankton choose the strategy of being self sufficient in addition to the lowering the cost of replication. Intelligence is more expensive strategy than these. Intelligence is selecting the behavior that will increase the chance of spreading gene according to the sensory input. This requires sensory system and central nerve system (CNS) or brain to process sensory information and control the actuators accordingly.

Non-Intelligent vs Intelligent biological agents. Please note intelligence requires the sensory system and neural information processing system
However, at first there are different levels in intelligence strategy. Agents such as earthworms have simple brains. It has hardcoded the mapping from sensory system to the corresponding actions using simple look-up table. This lookup table is updated with evolution. Therefore while there was no learning in individual agent, the species as a whole improved this hardcoded function. A good example will be an earthworm. Charles Darwin studied earthworms for over 30 years in his house and his book The formation of vegetable mould, throuth the action of worms sold more copies than the origin of species4. Earthworms have light receptors and vibration sensors. They move according to the light condition or the vibration caused by the moles. While this is drastic improvement over the random spreading of the phytoplankton, the problem with this approach is that adaptation is very slow because the update to the neural circuit happens through evolution.
The next level in the intelligence arms race is individual-level learning. Relying on evolution is too slow. If an individual agent can learn new rules such as a new type of food, it can surely increase the probability of successful gene spreading. However, to enable learning at the individual level, two functional modules are required.
The first is a memory to store newly developed rules. I conjecture the neocortex mainly serves this memory function. The second module is a reward system to judge the merit of the state. We stated that the goal of a biological agent is to spread genes. However, the correct assessment is not possible at the individual agent level. For example, an agent laid many eggs in a hostile environment that no descendant will survive. Still, the agent cannot know this because it succumbed before this happened. Therefore we need a function to indicate whether the current stimulus or state is good or bad. A reward system fills this gap by providing a proxy signal to approximate the probability of achieving goals. If an agent eats food, the stomach and blood glucose level information enter the reward center, and it generated a positive reward signal meaning this will be perhaps good for achieving goals. The signal indicates the new rule is good and needs to be stored in the memory. Later at a similar state, the newly added rule will be executed, which is the process of learning.
However, this implies that the environment does not provide a reward. Instead, it is an agent that produces a reward signal, which is the estimate of the current state by the agent about how valuable it is to achieve the ultimate goals. A dollar bill can be rewarding for some cultures but might not generate any reward to the tribal human who has never seen any money before. As for another example, when we eat three burgers for lunch, the reward for first and third burger will be different, even though it is the same object for the sake of the environment.
Therefore, the diagram Figure 1 should be updated as following.
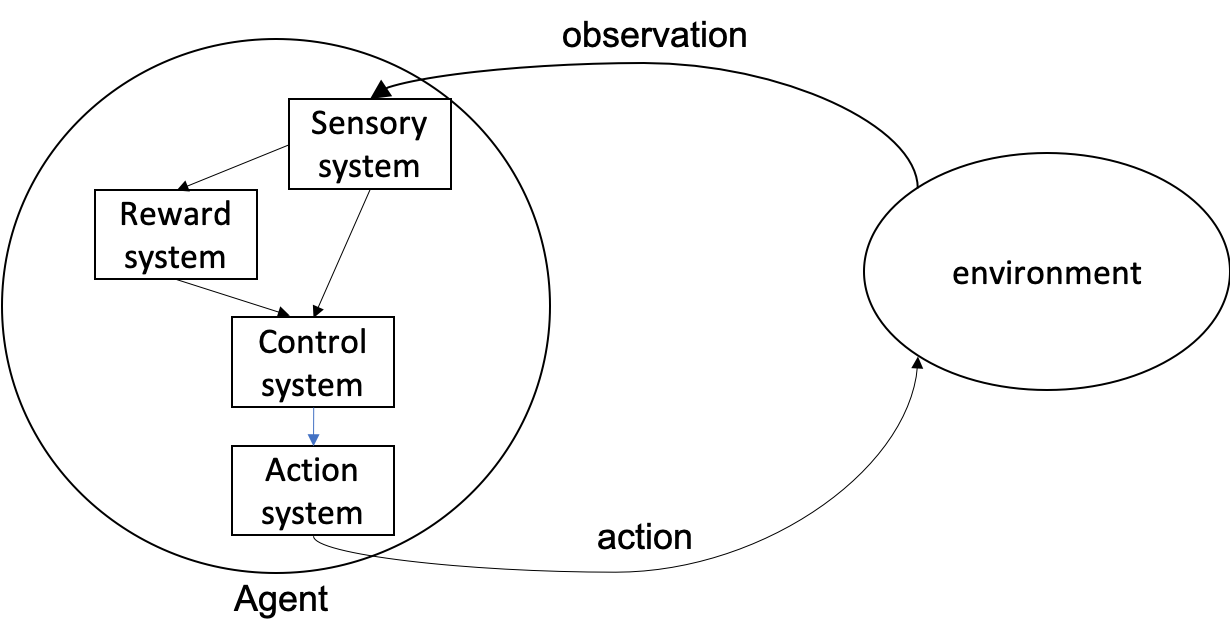
Revised relationship of the agent and environment. Environment provides an observation. Some observation is used for the reward system in the agent. The resulting reward signal and the sensory information is fed into the control system.
Many different factors affect the value of the current state, such as physical fatigue, appetite, sex, or safety. A tired agent may crave both rest and sex at the same time. It looks like estimating the final value of the current state considering various factors itself is the challenging problem, and nature is again using evolution to experiment with the optimal reward function.
Admittedly, authors are aware of this issue. Below are quotes from the discussions.
Strictly speaking, reward is an interpretation of the state of the environment. In this case, the environment is the universe, and clearly the universe does not have any notion of reward for particular agents. In humans this interpretation is internal, for example, that is experienced when you touch something hot. In which case, maybe it should really be a part of the agent rather than the environment? … A more accurate framework would consist of an agent, an environment and a separate goal system that interpreted the state of the environment and rewarded the agent appropriately.
Finally, I conjecture that human-level intelligence is not achievable with the maximizing the reward approach. I am planning to explain this in my new paper. The key idea is that while learning with reward is better than using evolution to improve your brain, it is still limited because the biological agent must experience the stimulus to learn it first hand. However, if you think about the hostile nature, learning with direct experience is a dangerous strategy, and what you can learn is limited. For example, a rabbit cannot try random action in front of the lion. It will be too late, and the rabbit’s experience cannot be transferred to other rabbits. Human-level intelligence tries to overcome this limitation by learning from others’ experiences with language. Language learning is related to the reward. As a summary, below is my hypothetical level of intelligence diagram.
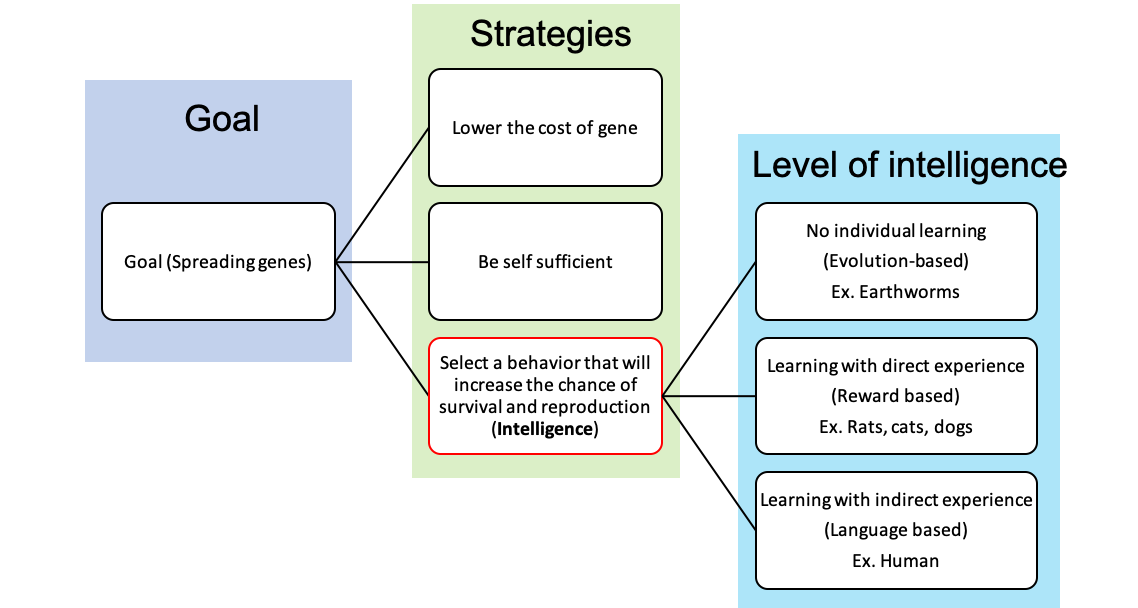
The three level of intelligence.
Below is my mindmap for the related papers to artificial general intelligence.
- How to Build a Brain: A Neural architecture for biological cognition. ^
- Legg, Shane, and Marcus Hutter. “A collection of definitions of intelligence.” Frontiers in Artificial Intelligence and applications 157 (2007): 17. link ^
- Gottfredson, L. S. (1997). Mainstream science on intelligence: An editorial with 52 signatories, history, and bibliography. Intelligence, 24(1), 13-23 ^
- Making sense of earthworm senses from Earthwormwatch.org. link ^