Publications
Filter by type:
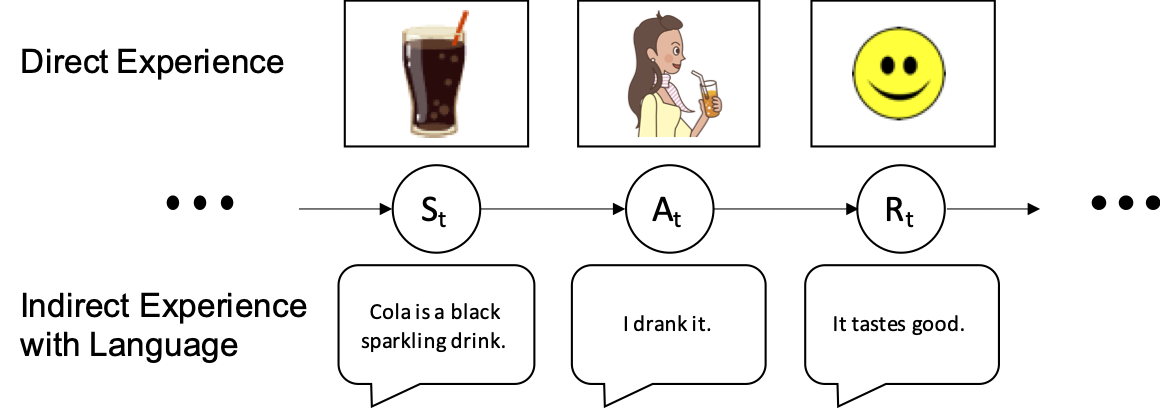
A Definition and a Test for Human-Level Artificial Intelligence
Despite recent advances in many application-specific domains, we do not know how to build a human-level artificial intelligence (HLAI). We conjecture that learning from others’ experience with the language is the essential characteristic that distinguishes human intelligence from the rest. Humans can update the action-value function with the verbal description as if they experience states, actions, and corresponding rewards sequences firsthand. In this paper, we present a classification of intelligence according to how individual agents learn and propose a definition and a test for HLAI. The main idea is that language acquisition without explicit rewards can be a sufficient test for HLAI.
arxiv,
2021

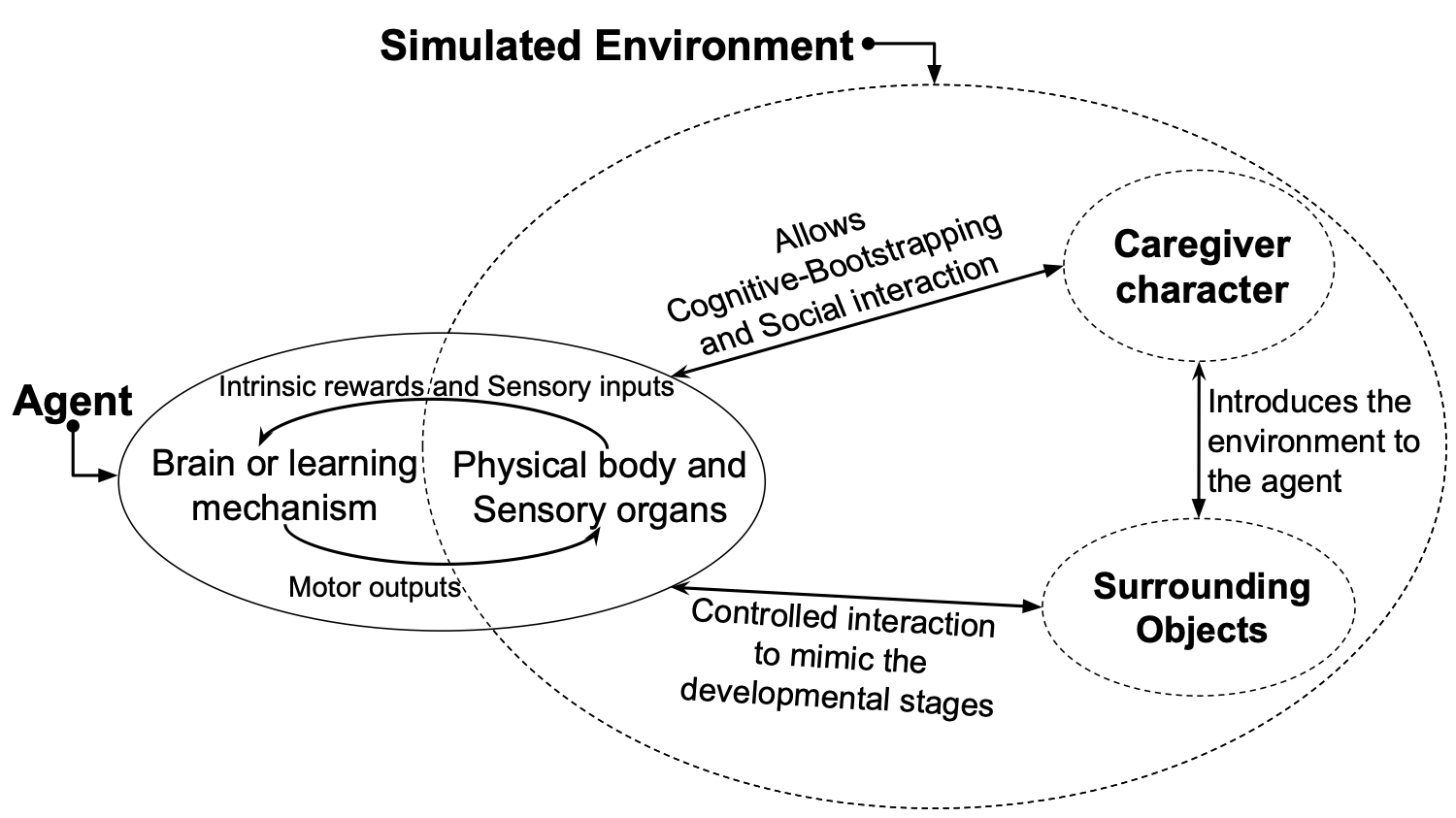

SEDRo: A Simulated environment for Developmental Robotics
Even with impressive advances in application specific models, we still lack knowledge about how to build a model that can learn in a human-like way and do multiple tasks. To learn in a human-like way, we need to provide a diverse experience that is comparable to human’s. In this paper, we introduce our ongoing effort to build a simulated environment for developmental robotics (SEDRo). SEDRo provides diverse human experiences ranging from those of a fetus to a 12th month old. A series of simulated tests based on developmental psychology will be used to evaluate the progress of a learning model. We anticipate SEDRo to lower the cost of entry and facilitate research in the developmental robotics community.
arxiv,
2018
ConceptVector: Text Visual Analytics via Interactive Lexicon Building Using Word Embedding
Central to many text analysis methods is the notion of a concept: a set of semantically related keywords characterizing a specific object, phenomenon, or theme. Advances in word embedding allow building a concept from a small set of seed terms. However, naive application of such techniques may result in false positive errors because of the polysemy of natural language. To mitigate this problem, we present a visual analytics system called ConceptVector that guides a user in building such concepts and then using them to analyze documents. Document-analysis case studies with real-world datasets demonstrate the fine-grained analysis provided by ConceptVector. To support the elaborate modeling of concepts, we introduce a bipolar concept model and support for specifying irrelevant words. We validate the interactive lexicon building interface by a user study and expert reviews. Quantitative evaluation shows that the bipolar lexicon generated with our methods is comparable to human-generated ones.
TVCG,
2018
Supporting comment moderators in identifying high quality online news comments
Online comments submitted by readers of news articles can provide valuable feedback and critique, personal views and perspectives, and opportunities for discussion. The varying quality of these comments necessitates that publishers remove the low quality ones, but there is also a growing awareness that by identifying and highlighting high quality contributions this can promote the general quality of the community. In this paper we take a user-centered design approach towards developing a system, CommentIQ, which supports comment moderators in interactively identifying high quality comments using a combination of comment analytic scores as well as visualizations and flexible UI components. We evaluated this system with professional comment moderators working at local and national news outlets and provide insights into the utility and appropriateness of features for journalistic tasks, as well as how the system may enable or transform journalistic practices around online comments.
CHI,
2016
Parallelspaces: Simultaneous Exploration of Feature and Data for Hypothesis Generation
We present ParallelSpaces, a novel method to explore bipartite datasets in both feature and data dimensions. This dyadic data is displayed as weighted bipartite graphs using scatterplots in two separated visual spaces, where each entity is positioned according to multi-dimensional properties of each entity or similarity in preferences. Selecting or navigating in one space is reflected in the other space, so that organic visual patterns can be formed to facilitate the characterization of underlying groupings. To aid visual pattern recognition we also overlay a contour plot based on kernel density estimation. We have implemented two instantiations of ParallelSpaces for (a) movie preferences, and (b) business reviews as Web-based visualizations. To validate the method, we performed a qualitative user study involving eleven participants using these Web-based tools to explore data and collect deep insights.
HICSS,
2016